
panDA
An abstraction layer for DAs to scale up with peace of mind.
panDA
Created At
Winner of

Nethermind - Data availability solutions

Avail - Best Project built with Avail

ETHGlobal - 🏆 ETHGlobal London Finalist
Project Description
panDA is an abstraction layer for Data Availability (DA) layers, built with additive security in mind. By using it, Layer 2 solutions and rollup ecosystems can scale efficiently and securely, leveraging different DAs as if they were one.
The cross-chain ecosystem has suffered greatly due to its reliance on non-adaptable solutions that were built without redundancy in mind and with lock-in to specific vendors - panDA helps addressing that from the start, ultimately enabling a future proof L2 ecosystem.
Key Features and Advantages:
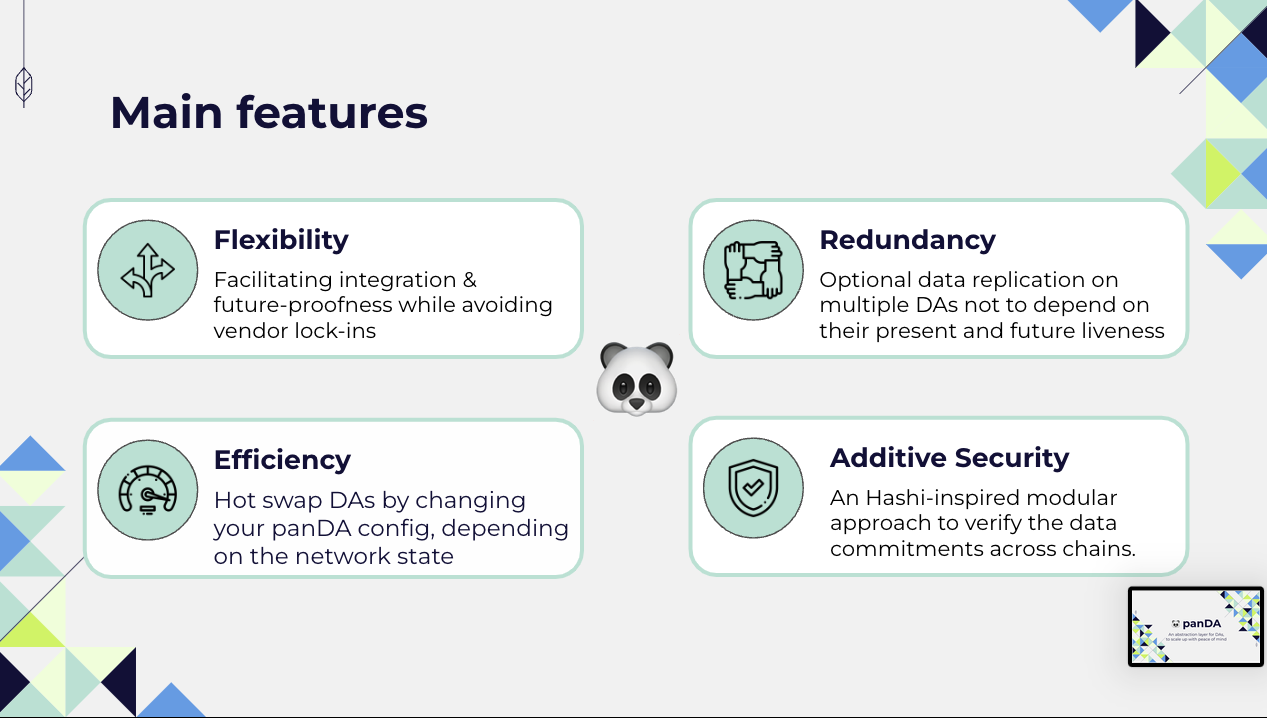
- Flexibility: panDA is created to provide seamless integration with different DA layers, and future-proofing capabilities, effectively eliminating the constraints of vendor lock-ins. This flexibility ensures that Layer 2 solutions and rollapps can adapt to the evolving landscape of Data Availability without being locked to specific platforms. If a new innovative DA gets invented your L2 can use it by simply changing the panDA configuration, with no additional changes required.
- Redundancy: panDA offers redundancy, giving the option to replicate data across multiple DA layers. This strategy mitigates the liveness risks associated with individual DAs, ensuring uninterrupted access and reliability when it matter the most.
- Additive Security: Drawing inspiration from the Hashi approach of additive security, panDA provides a robust framework for verifying data commitments across different chains. It is much safer than traditional solution as a bridging stack for propagating your state across chains.
- Efficiency: The platform allows to easily swap between DA layers, letting users modifying their panDA configuration in response to changing network conditions. This dynamic adaptability optimizes resource utilization, for example in case of network congestion.
How it's Made
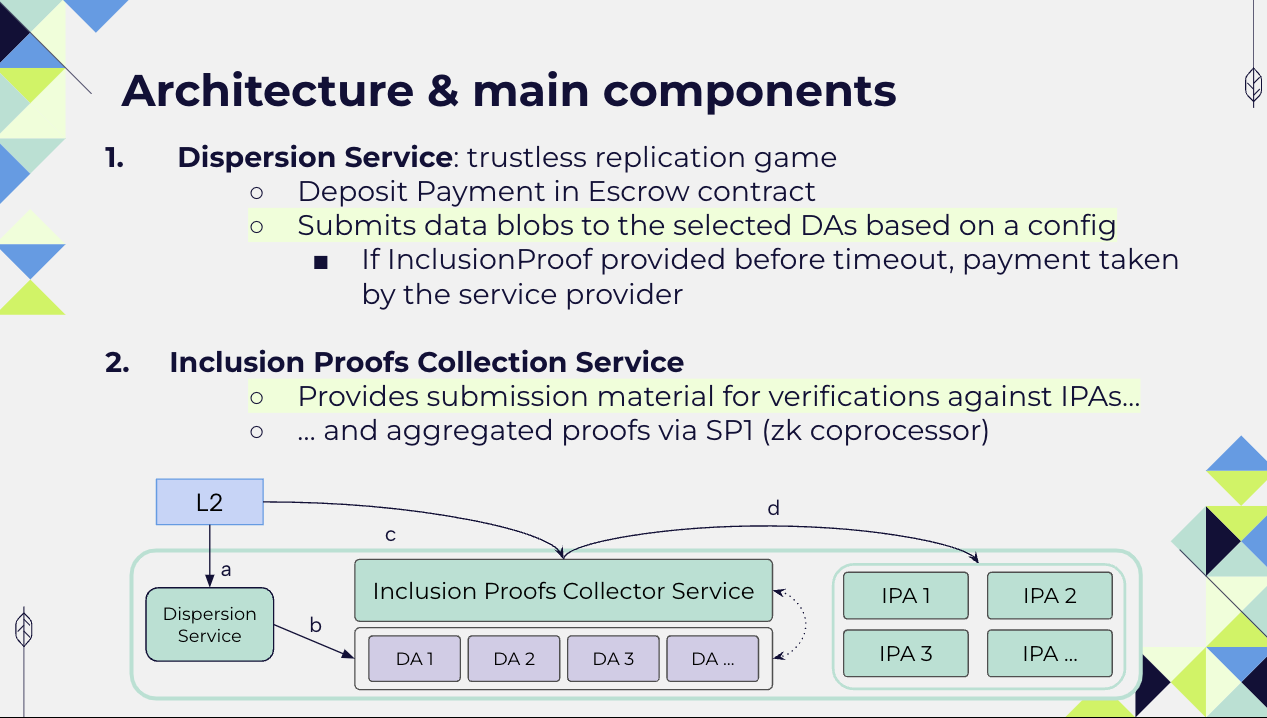
panDA consists of three main components:
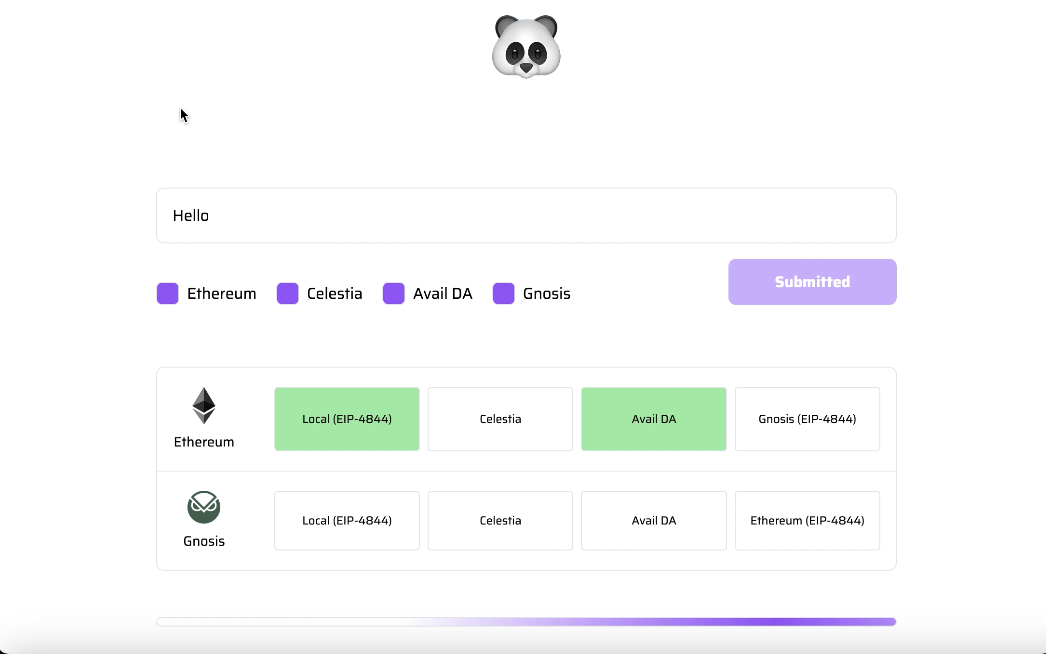
- the Dispersion Service which allows for the submission of the same data on different DA layers (namely Ethereum, Gnosis, Avail DA and Celestia)
- the Inclusion Proofs Collection Service which generates for specific blockchains different types of proofs that demonstrate the submission of data on the selected DA layers
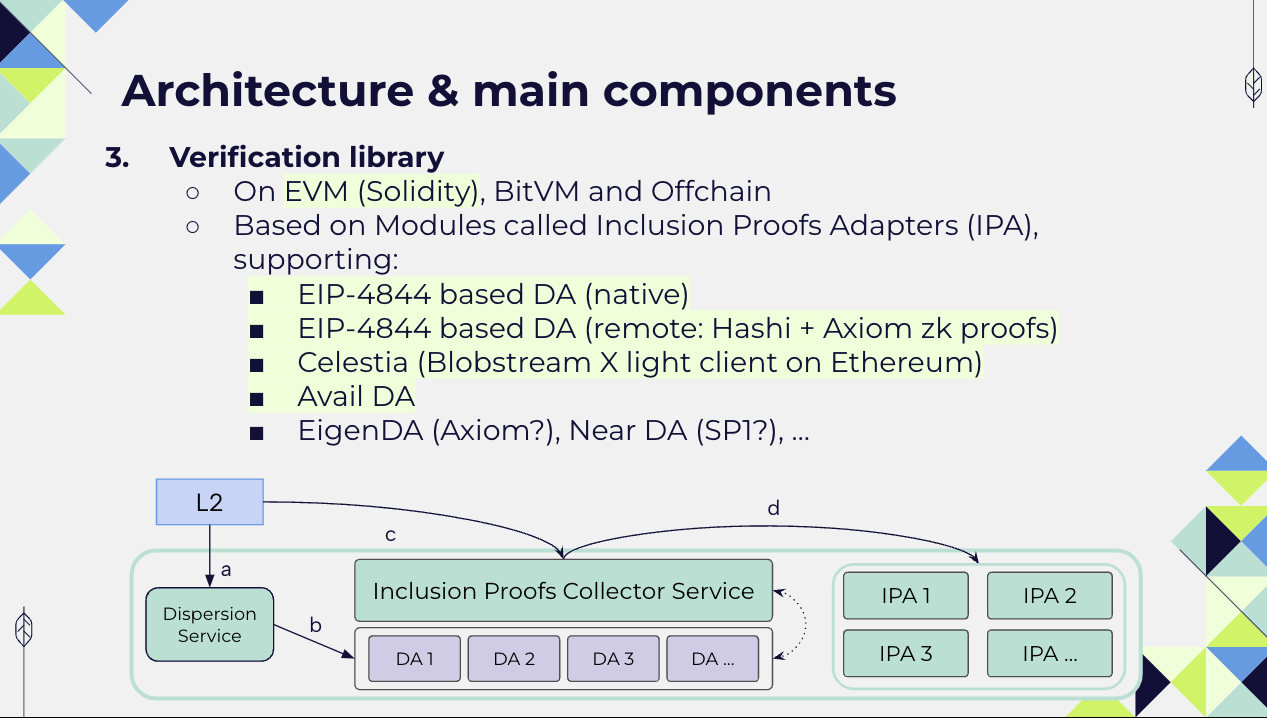
- the library which allows for the verification of the proofs; for example, we have built Inclusion Proof Adapters (IPAs) for the verification of different proof types on-chain.
We have used Avail DA as one of the supported DA layers and its bridge to create the IPA for verifying on Ethereum the submission of data on Avail DA.
We have used also Celestia as one of the supported DA layers, and Blobstream X to create the IPA for verifying on Ethereum the submission of data on Celestia.
We have also used the POINT_EVALUATION_PRECOMPILE_ADDRESS (introduced by EIP-4844) for the verification of KZG Proofs, which demonstrates the data availability of a blob.
Finally, we have used Axiom for the verification on different chains of ZK proofs of data availability on Ethereum.

