

TENTAI
sdk to shill AI models running on decentralized cloud instead of hugging face spaces
Project Description
[Slides] https://docs.google.com/presentation/d/1YWoTOcjl3Wo-mjzLuv9o8ioj1YzYBGJsz825ScEWeb4/edit#slide=id.g253560e2659_3_0
[Loom] https://www.loom.com/share/147e4cecf3f24a4f9e7f32583e1bf86a
Two problems are critical to solve today to democratize AI computing power.
Problem1: Deploying AI models is hard Problem2: Mass adoption for decentralized cloud is hard
We draw 2 inspirations from current solutions:
A) There are frameworks like gradio which allow AI model developers to write python DSL and create a hosted linked to share their model on hugging face spaces immediately. Building model binaries are often error prone and access to GPU hardwares are limited, also generally these developers are neither web developers nor DevOps, so there is huge value simplifying the process and bridge the knowledge gap required and the community thrives with these interactive models to develop on each other.
Meanwhile, this is relying on centralized service which is costly when scaled and usage/FinOps data are not shared among community.
B) Infrastructure-as-Code tools proved to have tremendous values in DevOps engineering and there is a trend where AWS CDK / Terraform / Pulumi share not only basic cloud provider building blocks but also readily consumable high level constructs, architecture recipes with best practices in security and performance. For mass adoption of decentralized computing it is key to tap on existing developer communities and use tools they are mostly familiar with. Migration cost will be low if they could go hybrid in traditional cloud providers / decentralized computing reusing existing toolkit like pulumi. For instance it is possible to continue to serve today's workload while introduce use cases related to Compute Over Data at edge or archiving particular datasets onto IPFS with existing cloud management process.
TENTAI as my solution to empower developers -- SDK to shill your AI Models running on decentralized computing.
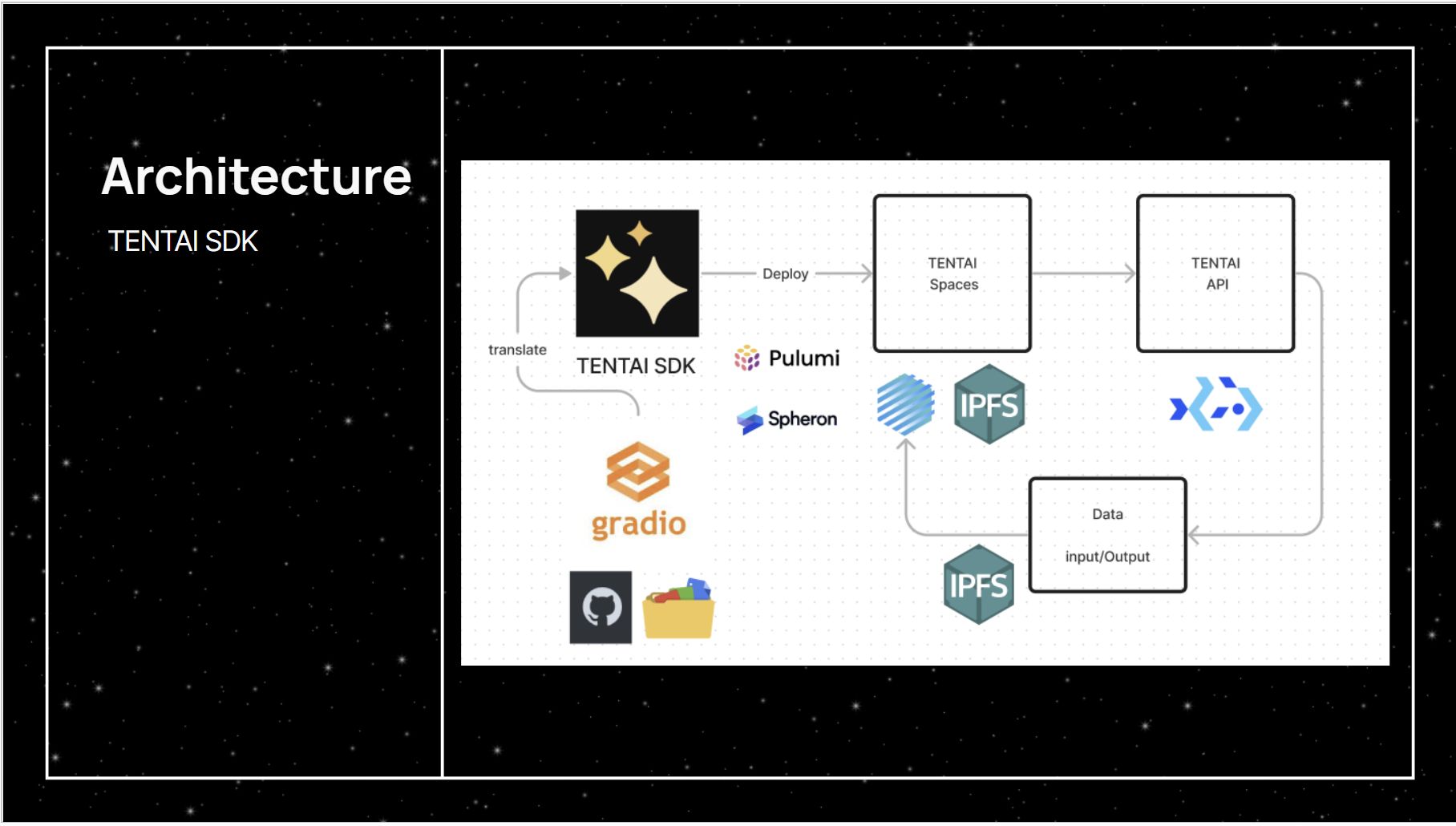
Using TENTAI, with only a few lines of code, developer is able to customize the model and deploy it onto IPFS using Spheron and execute jobs on bacalhau. Similar to gradio, a UI will be built according to user's specification on input and outputs with python. This site is statically generated and hosted on IPFS, and it has API to connect with bacalhau that maps the input to corresponding job parameters. The AI model specified will be generating a docker image which can be used by bacalhau in a job-based fashion, where all such infrastructure dependency are managed and orchestrated with the pulumi fraemwork.
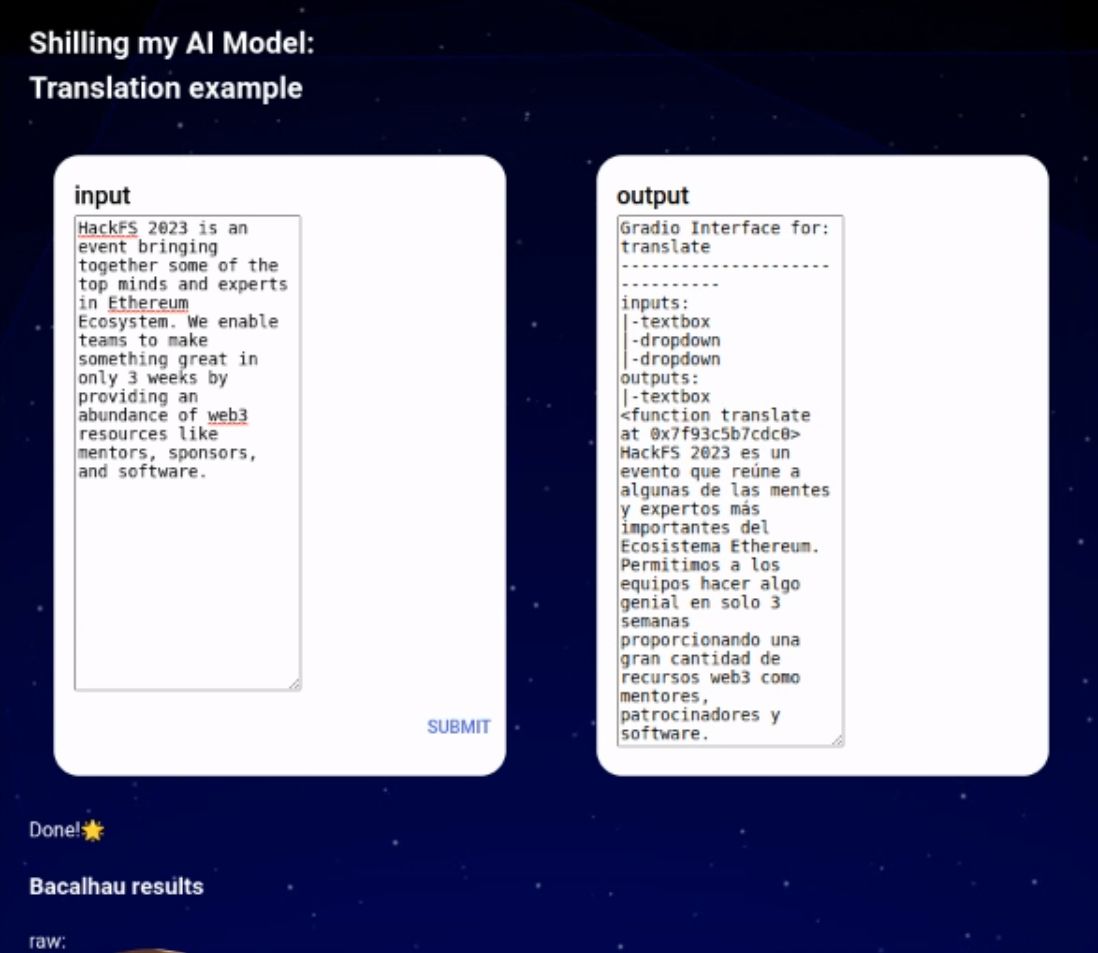
For example, with translations (transformers) template, a UI with one input text box and one output text book is generated where input will be incorporated by Spheron
into a job and submit to bacalhau, which will execute the model facebook/nllb-200-distilled-600M with decentralized computing and flush results onto IPFS. The results is then retrieved via Saturn on the browser via service worker.
This paradigm is able to support a wide range of models and frameworks since bacalhau is supporting docker/WASM the most popular container technologies. Role of TENTAI is to easily bridge or wrap models from gradio or other frameworks into docker/WASM and improve the DX and cost effectiveness on inference
I believe this tool has potentials to provide solid alternative for AI model deployment and given all storage and compute deals are on-chain, heatmap of usage / utilization can be derived where community could improve the design and models.
As inspired by the waterlily.ai project, it is also possible to incentive developers to share their models and get rewarded with inference usages by deploying related Filecoin contracts
How it's Made
A sample application is defined in (apps/hub/src/tentai-translations-demo.py)
When user want to deploy model to TENTAI, they only need to manipulate 2 python files
- model/run.py = their custom model pipelines in python (which is gradio compatabile)
- main.py = infrastructure required, e.g. template to use, site name and docker image to use/build.
For the 1st component (model), it is intentionally copied from gradio official examples to illustrate we could use wrapper to translate existing models/interfaces to deploy. The custom model file are packed into Docker with a template (packages/gradio-adapter-py)
For the 2nd component, Each site is built with nextjs using static site generation. At build time, the template repository (packages/template/tentai-template-next-ts) is being cloned, and related configurations are generated and injected as tentai.config.json which then pick up by site generation with static props. This allow sites of different layout i.e. input/output combination be generated programmatically while most frontend features are shared.
The webapp include a service worker from Saturn, which can achieve faster CDN style retrieval for result from bacalhau.
A pulumi plugin is developed to provision the docker image and web app, with high level recipes (constructs) to build on top of templates. It has great multi cloud support and thus developers are able to use familiar language to their infrastructure, from a fully decentralized. Under the hood, the plugin is written in typescript and details of inner working provisioning the app are modulaized, for example after building with nextjs template, Spheron api is used to upload & host the static site. Such typescript plugin is followed by code generation (in go script) to create python sdk as supported by pulumi. Overall it reduce context switch as developer can write python for both the AI model and related infra provisioning.
The site is designed to be serverless, which is different from gradio which use a running server design to support more stable and diverse set of hosting. Also as streaming at bacalhau is still under active development, a long-running job on bacalhau to host APIs and further communicate with other jobs could make sense in future.
Besides, there is a proxy to invoke the generic endpoint of Bacalhau and submit job for HTTPS & CORS consideration.
Latency is slightly high at demo but that is because we are limited to single gpu with bacalhau generic endpoint and deal, performance could be improved when more incentives are deployed or with locality where there are public cached data among nodes.

