
braid
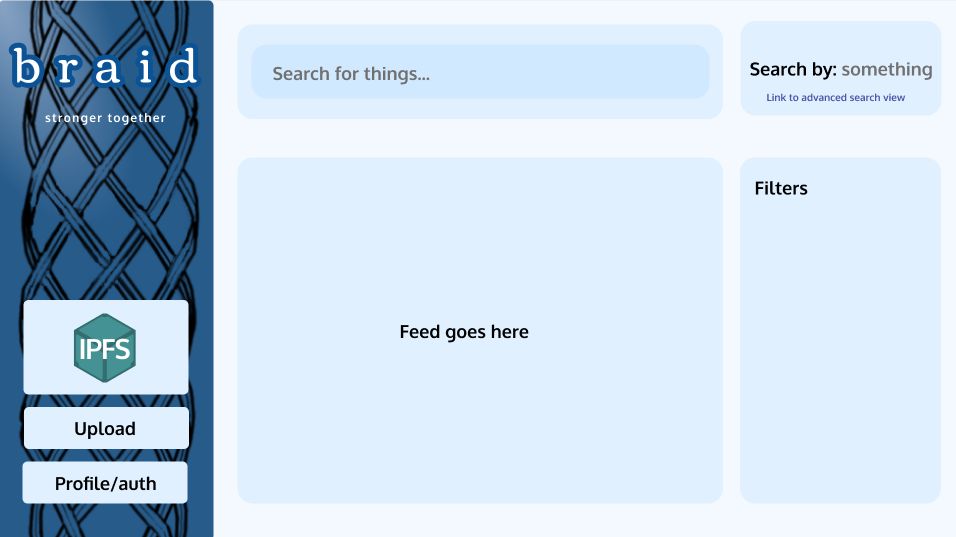
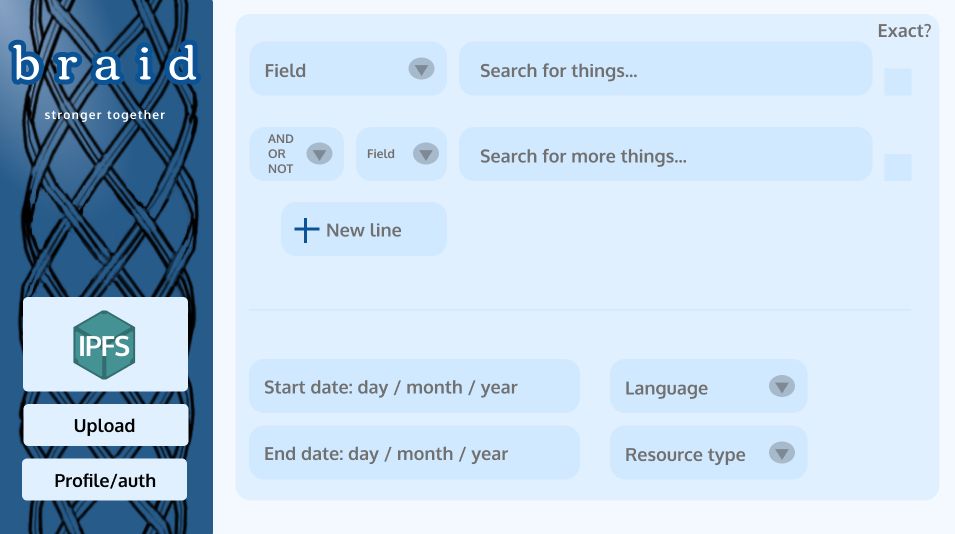
Archive science papers on IPFS , search for them, comment and collaborate
Project Description
As the incredible pace of innovation continues to accelerate we need an archive that can keep up. We need a modern archive which lets you post early versions of your paper before publication in a journal, receive feedback from a global network of peers, and permanently store the information somewhere anyone can access.
That's why we're leveraging the technology of IPFS — blockchain-based, decentralized, immutable, censorship-resistant file storage— to store and retrieve papers.
Further, the multi-billion dollar science publishing industry is controlled by a few entrenched publishers who take advantage of scientists by requiring them to review papers for the journal for free. These publishers charge exorbitant fees for a scientist to apply to publish with them and further fees for people to access the papers.
At braid, we believe in free and open information. And we believe in paying people for their work.
We believe that the most powerful force behind human progress is human ideas. We believe the best ideas happen through powerful collaboration between independent thinkers. We believe that any idea — no matter how good or who came up with it — can still be improved.
That's why we're creating a platform for improving ideas — a platform where people can go to weave observations, insight, and reason together. A platform for anyone who wants to be a scientist, scholar, or simply curious.
How it's Made
Our project relies on a few core technologies:
-
Web3.Storage for uploading papers to IPFS
-
Svelte as our frontend
-
OrbitDB for IPFS-based peer-to-peer database
Overall, we found Web3.storage easy to use and interact with.
We found Svelte easier to work with than a traditional web framework like React. Svelte loads as a single page application and actually is a compiler. This means that it creates static assets which are easier to render than dynamic assets. When combined with Webpack, this makes Svelte particularly good to use for deploying decentralized frontends which can render statically.
We struggled with OrbitDB because it is still an alpha software. It creates databases in the browser and uses IPFS pubsub to sync databases with peers. We are really excited about the potential for this technology but may switch to using MongoDB until OrbitDB has seen further development.

