
Botblock
With the rise of AI, the general public is now aware of it and how much money companies are making/loosing out of it. But how do they gather information to keep relevant and up to date? keep looking into this project to find out
Project Description
With the rise of AI, the general public is now aware of it and how much money companies are making/loosing out of it.
But how do they gather information to keep relevant and up to date?
AI companies and developers generally make use of web crawlers that get into websites and extract the information that they require for their models. The most important crawlers out there are GPTBot (by OpenAI) and CCBot (by Common Crawl).
How it's Made
We did the project using NextJS for the frontend; Hardhat for creating and testing the smart contracts Chainlink Upkeeps to resolve orders Web3Auth to implement Account abstraction Polygon mumbai Scroll sepolia Arbitrum goerli to deploy contracts.
readme:
🤖 BotBlock
Get paid by AI for the content you create!
🤔 Why?
With the rise of AI, the general public is now aware of it and how much money companies are making/loosing out of it.
But how do they gather information to keep relevant and up to date?
AI companies and developers generally make use of web crawlers that get into websites and extract the information that they require for their models.
The most important crawlers out there are GPTBot (by OpenAI) and CCBot (by Common Crawl).
🤺 How do we fight it?
To disallow crawlers to scrape your site, website's owner must update their robots.txt static file. For example, to block GPTBot it should have the following:
User-agent: GPTBot
Disallow: /
As a good practice, crawlers need to check the robots.txt file to know if they are allowed to get their contents or not. Thus, this should stop them from doing so.
In BotBlock we think that securing your website is important and that it should be super easy to do. Because of that, we have a tool to add these to your existing
robots.txtso you don't have to, you would just use the tool and upload the giventxt
💸 Is there a way to give them the content but just not for free?
That's when BotBlock comes in. The goal of this product is to enable Content Creators to monetize their content for AI developers.
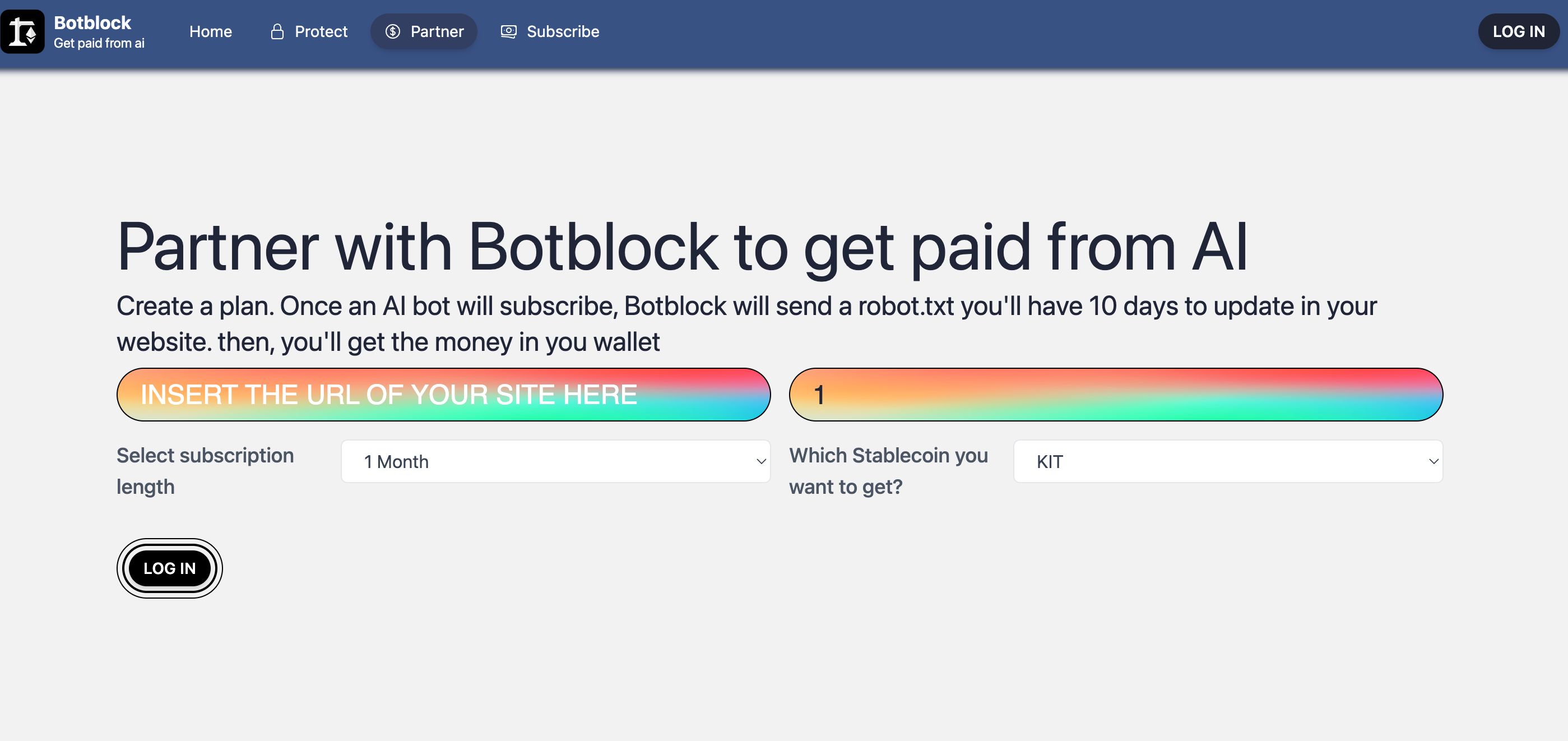
For that we created our main feature at BotBlock, "unlock". How does it work?
- Content creators enter the site (at
/unlock/partner) to partner with us to block the site. - Assuming that they already updated their
robots.txt, user creates a subscription plan that anyone can buy to give access to their bot to the site. - After the plan is created, the AI dev/company can enter the site (at
/subscribe) to see the list of plans and their pricing. - The AI dev/company select the site they want to crawl and purchases the subscription.
⚙️ Okay, so what happens after buying the subscription?
At the time of writing this step is still under development
After the purchase of the subscription plan, the Content Creator gets notified of it and they will have 7 days to update their robots.txt to allow the AI dev/company do their crawling.
- If the Content Creator doesn't do that, BotBlock will return the money to the AI dev/company.
- Otherwise, BotBlock will send the money to the Content Creator and the AI dev/company will be notified to start their crawling.
🧑💻 Running the repo
The repo consists of 3 packages:
- express
- hardhat
- nextjs
Express
The express server is there to fetch Content Creator's robots.txt and then let our main page retrieve them from there. Express server should be online via an ngrok tunnel on https://correctly-leading-chicken.ngrok-free.app, but if it ain't the user should browse to express and:
- Install dependencies (
yarn install) - Start the server (
yarn start) - Go to
RobotsContext.tsxand change the ngrok url with their localhost + port
NextJS
The main website was developed using NextJS. To run it locally you can do:
- Install dependencies (
yarn install) - Add the env variable of
NEXT_PUBLIC_WEB3AUTH_CLIENT_IDat.env.localwith your Web3Auth client ID - Start the development server (
yarn dev) - Access the site on
localhost:3000(or following the instructions of the server after starting it).
Hardhat
You should not need running this side of the project for demo purposes.
Smart Contracts
Arbitrum Goerli
BotblockMarket: 0xabe0D51F2f537c14CE782B26Fb3A59EB4A563316
keykoInnovationToken: 0x8337E43E0E25eeDFA47b403Bdfe3726b8C1BB59b
Polygon Mumbai
BotblockMarket: 0xEe9168F366c6AF173ee330C4f4214452BEF0E5DB
keykoInnovationToken: 0xbf24A1ed20160b2fe4f13670Fd95002d9f9f4680
Scroll Sepolia
BotblockMarket: 0x56f4287a546aC5c6077eA9542A80017b16882441
keykoInnovationToken: 0xa7CC37619A324A10d29021C0ad50E501D5d4e976
Chainlink
Functions to be called by upkeep
Available on commit 34b6da
- mumbai Upkeep: 0x2565b778779F48f12B1e1983EFb4D11Cd167430A
- arbitrum Upkeep: 0x065Beb95Fff0CF1e841cF44363F060a01Ad4Eb00

